Graph Theory Problem
I came across a graph theory problem at work this week, and decided to blog about it to help me sort it out. At first I didn’t think of it as a graph problem, but that’s how these problems often go, shrouded in disguise and all. But I digress.
The problem is this. Considering the following directed graph, which nodes are the most senior ancestors (speaking in tree terms, of course)?
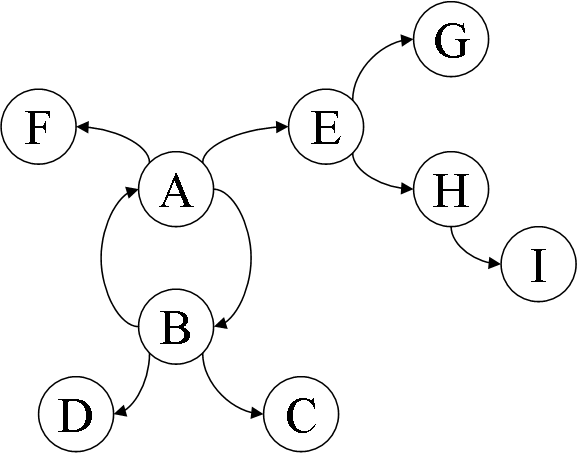
The answer is that nodes A and B are the most senior, meaning they have the most number of descendants in their sub-trees. This becomes obvious if we draw the same graph this way:
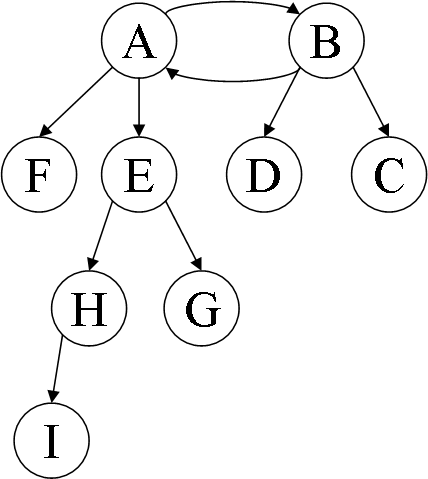
I’m trying to discover an algorithm to identify the senior most nodes given any directed graph. The graph is given as an edge list, like this:
- A -> B
- A -> F
- A -> E
- E -> H
- E -> G
- B -> A (notice the cycle here back to A)
- B -> D
- B -> C
- H -> I
So there’s the problem. I’m looking for an algorithm that will find the top-most nodes given any directed graph. In the case where there is only a single top-most node, it’s easy, but that’s just one case, and I want a general solution. Also, the graph need not be fully reachable from any node. It could be two or more non-connected graphs.
If you have an idea for an elegant solution, please post it in the comments below. I’ll post my own solution next week.
Happy graphing!
Edit:
After thinking about the problem a bit more, I thought I’d add another example with some corner cases that my solution will need to consider. If you look below, you’ll see a graph with a more complicated cycle and a non-contiguous section. The nodes I expect the algorithm to discover are shown in green:
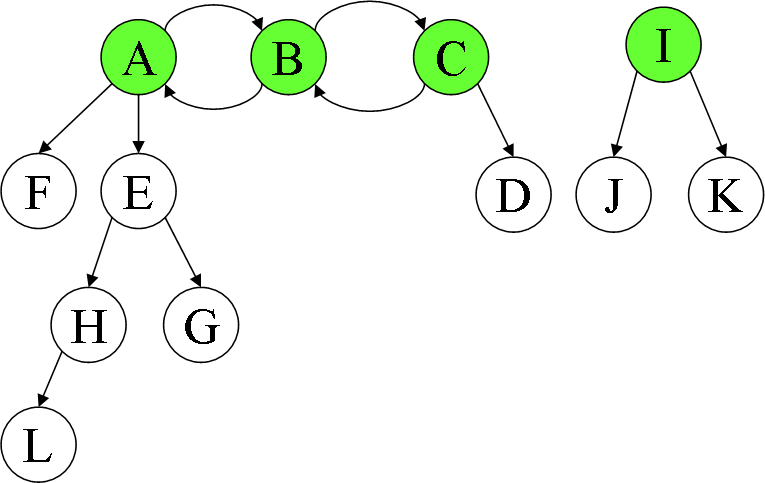
Here are the edge pairs:
- A -> B
- A -> E
- A -> F
- E -> H
- E -> G
- B -> A
- B -> C
- C -> B
- C -> D
- I -> J
- I -> K
- H -> L
22 comments to “Graph Theory Problem”
What do you do about the infinite loop? I don’t see any mention of a rule to only traverse any given node once for a particular start point.
There was intentionally no mention of such a rule. The only objective is to find the solution by whatever means necessary.
My first guess would be to run a Depth First Search on each node–keeping track of pre and post numberings. That node’s “score” would be the post – pre ordering numbers. I guess you could actually just increment a counter each time you postvisit a node, since the previsit number of the root node would always be 1.
So, a recursive version would be something like this:
for v in G:
score(v) = 0
dfs(v)
def dfs(v):
mark v as visited
for all i adjacent to v such that i not visited
dfs(i)
increment score(v)
An instruction “unmark everything” should go after “score(v) = 0)
Bugs probably included, no additional charge :)
def influences(graph): sources = set([edge[0] for edge in graph]) sinks = set([edge[1] for edge in graph]) parents = dict([(s, set()) for s in sinks]) inf = dict([(s, set()) for s in sources]) updated = set() for (a, b) in graph: parents[b].add(a) inf[a].add(b) updated.add(a) while updated: n = updated.pop() hits = inf[n] for p in parents[n]: phits = inf[p] if hits.issubset(phits): continue phits.update(hits) updated.add(p) return inf def reaches(graph): return [(a, len(b)) for (a, b) in influences(graph).iteritems()] def supernodes(graph): r = reaches(graph) x = max([b for (a, b) in r]) return [a for (a, b) in r if b == x] graph = [('a', 'b'), ('a', 'f'), ('a', 'e'), ('e', 'h'), ('e', 'g'), ('b', 'a'), ('b', 'd'), ('b', 'c')] print supernodes(graph)Crap, my stupid blog strips white space from the beginning of comment lines, so your python code got munged. Sorry. I think you may be able to indent with HTML codes, though…
Anywho, I posted another example problem that should make the solution I’m looking for a bit more clear.
David,
Your algorithm works perfectly for contiguous graphs, but not for non-contiguous graphs (like the third example graph I posted above).
–Dave
I think the following will work. Maybe not the most CPU efficient, but I cannot think of a better way:
Do Warshall’s algorithm (http://en.wikipedia.org/wiki/Floyd-Warshall_algorithm) to build the connectivity matrix. Then for each node count the number of descendants (node A is a descendant of node B if the connectivity matrix has 1 in the [B][A] cell), and find the maximum.
This is O(N^3) so not that great, and uses a lot of RAM to (N^2)
Sasha,
In my third figure, this algorithm would not find node “I”, since it has a shorter descendant tree than A (in terms of tree height), but “I” is nonetheless in the solution set. Correct me if I’m wrong.
–Dave
Well I think it would be easiest in two passes
1st pass all nodes that have no link to them unless it is a reciprocal link
is marked as a top node.
2nd pass though those nodes marked as top nodes confirm that the reciprocal linking node is also a top node.
does that work?
Daniel,
I think your approach has promise. In fact, your “1st pass” is how I originally implemented my algorithm at work, and didn’t realize I needed to have a second pass until I found instances of reciprocal nodes (which of course caused my algorithm to not find *any* nodes, since the only root nodes it discovered were actually reciprocally linked in some graphs).
–Dave
I’m approaching this problem with Python, as a previous commenter has done. However, I think your expected outcomes, and what you’re asking for aren’t lining up. So, I’m commenting to clarify. You want the top most nodes- AKA: the nodes with the most descendants?
If that is the case, in your first example, B is the top-most node to As subtree, and A is the top most node to Bs subtree. In your second example, there are only two top-most nodes that I see: C and I. A is a descendant of B which is a descendant of C. A does not have the most in that tree, as B has one more (A), and B is not have the most in that tree, as C has two more (B and D). Thus, C is our top-most node.
At least, that is the direction my algorithm has been going.
Aaron: Stating the problem as “the nodes with the most descendants” is misleading, as you suggest. I’m struggling to verbalize the problem myself, since obviously my graph theory is weak, so I hope the pictures (especially the third one) speak for themselves.
Let me explain the problem’s context. I am developing a GUI that uses a common tree view, like what you might see in a file browser. I am given a graph like the ones pictured above, and need to translate that into the tree view display full of expandable and collapsible nodes (with possibly multiple root nodes).
Does that help at all?
Dave:
Warshall algorithm will find all nodes. It does not really care if the graph is fully connected since it works with a connectivity matrix rather than starting from a node and traversing the graph. Basically the idea is that for each node we pour colored water into it and then see which other nodes eventually have water of that color.
Sasha:
The Warshall algorithm will certainly find all the nodes and their descendants’ tree height. I don’t argue that. What I find wrong with your approach is measuring the depth of each nodes’ descendants tree and choosing the parent nodes with the maximum height. In the third figure above, that would omit node “I”, not because “I” is part of a disconnected graph, but because its tree height is smaller than that of “A”, “B”, and “C”.
The `influences` function is unchanged, but `supernodes` has been adapted. There are plenty of optimizations around the set operations (eg, pushing only recently added nodes up to a parent, instead of all nodes), but the basic algorithm is (I think) pretty efficient.
def influences(graph): sources = set([edge[0] for edge in graph]) sinks = set([edge[1] for edge in graph]) parents = dict([(s, set()) for s in sinks]) inf = dict([(s, set()) for s in sources]) updated = set() for (a, b) in graph: parents[b].add(a) inf[a].add(b) updated.add(a) while updated: n = updated.pop() hits = inf[n] for p in parents.get(n, []): phits = inf[p] if hits.issubset(phits): continue phits.update(hits) updated.add(p) return inf def supernodes(graph): inf = influences(graph) reach = dict([(a, len(b)) for (a, b) in inf.iteritems()]) supers = set() while reach: x = max([b for (a, b) in reach.iteritems()]) print 'max', x new = [a for (a, b) in reach.iteritems() if b == x] print 'new', new supers.update(new) for n in new: if n in reach: del reach[n] for m in inf[n]: if m in reach: del reach[m] print reach return supers graph = [('a', 'b'), ('a', 'e'), ('a', 'f'), ('b', 'a'), ('b', 'c'), ('c', 'b'), ('c', 'd'), ('e', 'g'), ('e', 'h'), ('h', 'l'), ('i', 'j'), ('i', 'k')] print supernodes(graph)And base64-protected :) —
ZGVmIGluZmx1ZW5jZXMoZ3JhcGgpOgogICAgc291cmNlcyA9IHNldChbZWRnZVswXSBmb3IgZWRn
ZSBpbiBncmFwaF0pCiAgICBzaW5rcyA9IHNldChbZWRnZVsxXSBmb3IgZWRnZSBpbiBncmFwaF0p
CgogICAgcGFyZW50cyA9IGRpY3QoWyhzLCBzZXQoKSkgZm9yIHMgaW4gc2lua3NdKQogICAgaW5m
ID0gZGljdChbKHMsIHNldCgpKSBmb3IgcyBpbiBzb3VyY2VzXSkKICAgIHVwZGF0ZWQgPSBzZXQo
KQoKICAgIGZvciAoYSwgYikgaW4gZ3JhcGg6CiAgICAgICAgcGFyZW50c1tiXS5hZGQoYSkKICAg
ICAgICBpbmZbYV0uYWRkKGIpCiAgICAgICAgdXBkYXRlZC5hZGQoYSkKCiAgICB3aGlsZSB1cGRh
dGVkOgogICAgICAgIG4gPSB1cGRhdGVkLnBvcCgpCiAgICAgICAgaGl0cyA9IGluZltuXQogICAg
ICAgIGZvciBwIGluIHBhcmVudHMuZ2V0KG4sIFtdKToKICAgICAgICAgICAgcGhpdHMgPSBpbmZb
cF0KICAgICAgICAgICAgaWYgaGl0cy5pc3N1YnNldChwaGl0cyk6IGNvbnRpbnVlCiAgICAgICAg
ICAgIHBoaXRzLnVwZGF0ZShoaXRzKQogICAgICAgICAgICB1cGRhdGVkLmFkZChwKQoKICAgIHJl
dHVybiBpbmYKCmRlZiBzdXBlcm5vZGVzKGdyYXBoKToKICAgIGluZiA9IGluZmx1ZW5jZXMoZ3Jh
cGgpCiAgICByZWFjaCA9IGRpY3QoWyhhLCBsZW4oYikpIGZvciAoYSwgYikgaW4gaW5mLml0ZXJp
dGVtcygpXSkKICAgIHN1cGVycyA9IHNldCgpCiAgICB3aGlsZSByZWFjaDoKICAgICAgICB4ID0g
bWF4KFtiIGZvciAoYSwgYikgaW4gcmVhY2guaXRlcml0ZW1zKCldKQogICAgICAgIHByaW50ICdt
YXgnLCB4CiAgICAgICAgbmV3ID0gW2EgZm9yIChhLCBiKSBpbiByZWFjaC5pdGVyaXRlbXMoKSBp
ZiBiID09IHhdCiAgICAgICAgcHJpbnQgJ25ldycsIG5ldwogICAgICAgIHN1cGVycy51cGRhdGUo
bmV3KQogICAgICAgIGZvciBuIGluIG5ldzoKICAgICAgICAgICAgaWYgbiBpbiByZWFjaDogZGVs
IHJlYWNoW25dCiAgICAgICAgICAgIGZvciBtIGluIGluZltuXToKICAgICAgICAgICAgICAgIGlm
IG0gaW4gcmVhY2g6IGRlbCByZWFjaFttXQogICAgICAgIHByaW50IHJlYWNoCiAgICByZXR1cm4g
c3VwZXJzCgpncmFwaCA9IFsoJ2EnLCAnYicpLAogICAgICAgICAoJ2EnLCAnZScpLAogICAgICAg
ICAoJ2EnLCAnZicpLAogICAgICAgICAoJ2InLCAnYScpLAogICAgICAgICAoJ2InLCAnYycpLAog
ICAgICAgICAoJ2MnLCAnYicpLAogICAgICAgICAoJ2MnLCAnZCcpLAogICAgICAgICAoJ2UnLCAn
ZycpLAogICAgICAgICAoJ2UnLCAnaCcpLAogICAgICAgICAoJ2gnLCAnbCcpLAogICAgICAgICAo
J2knLCAnaicpLAogICAgICAgICAoJ2knLCAnaycpXQoKcHJpbnQgc3VwZXJub2RlcyhncmFwaCkK
David:
That looks pretty. I think it works just right (still looking it over).
–Dave
Dave:
I am not sure I understand what you are saying. The Warshall algorithm will tell you for each pair of nodes (A,B) if A is a descendant of B. This allows you to go through all the nodes and compute descendant counts for each node. Once you have the counts, the most senior node is the one with the maximum number of descendants.
But actually looking at your graph with the “I” node, I realize that you were asking a different question. I think you need to formulate it more precisely, though. What exactly makes a node senior? Give a rule that will make node I more senior than node E.
One idea – split the graph into fully connected sub-graphs that are not connected with each other, and then declare a node to be “senior” if it has the most descendants in its sub-graph. In that case, the problem is split in two – build the connectivity matrix with the Warshall algorithm, then sub-divide the result. Subdivision can be done like this:
For each remaining node, pick the one with the most descendants. Exclude it along with all of its descendants. Repeat until empty.
If I understand the problem posed, it looks like you’re dealing with an event-driven finite state machine. I believe that any senior node will meet one of two criteria:
a) the node x has no direct predecessors (or Parents), i.e. P(x) = ∅
b) the node’s parents are a subset of its descendants i. e., P(x) ⊆ D(x)
I would evaluate each ordered pair’s head and tail to create a Parent set and Successor set for each node. Then I’d evaluate each set to see if it met the senior node criteria.
Processing your directed graph, seems to yield the proper result as do the corner cases I tried.
Carl,
That sounds promising. I think I’ll code that up, and see how it works with my real data.
By the way, in case you’re wondering, I’m using Qt to build a QTreeView (QStandardItem-based) to represent the graph in tree form. My data is in the form of a QMap<Object*,QSet<Object*>> such that each of the map’s keys maps to a set of children. The map is in no particular order.
–Dave
I did a quick and dirty in VBA if it helps.
Enum PairType head = 0 tail = 1 End Enum Dim Nodes As New Scripting.Dictionary Dim Parents As New Scripting.Dictionary Dim Successors As New Scripting.Dictionary Dim Pairs As Variant 'Variant array of ordered pairs Sub InitPairs() 'Each pair is comprised of a head/tail duple Pairs = Array( _ Array("AB", "A", "B"), Array("AE", "A", "E"), Array("AF", "A", "F"), _ Array("BA", "B", "A"), Array("BC", "B", "C"), _ Array("CB", "C", "B"), Array("CD", "C", "D"), _ Array("EG", "E", "G"), Array("EH", "E", "H"), _ Array("HL", "H", "L"), _ Array("IJ", "I", "J"), Array("IK", "I", "K") _ ) End Sub Sub Main() Dim pr, i As Long, node As Variant, hasParent As Boolean Dim parStr As String, parCh As String, succStr As String, Missing As Boolean 'Init pairs and create node list InitPairs For Each pr In Pairs If Not Nodes.Exists(pr(head)) Then Nodes.Add pr(head), pr(head) If Not Nodes.Exists(pr(tail)) Then Nodes.Add pr(tail), pr(tail) Next pr ' For Each node In Nodes Parents.Add node, "" Successors.Add node, "" Next node For Each pr In Pairs If (InStr(Parents(pr(tail)), pr(head)) = 0) Then Parents(pr(tail)) = Parents(pr(tail)) & pr(head) End If If (InStr(Successors(pr(head)), pr(tail)) = 0) Then Successors(pr(head)) = Successors(pr(head)) & pr(tail) End If Next pr For Each node In Nodes parStr = Parents(node) Missing = False succStr = Successors(node) For i = 1 To Len(parStr) parCh = Mid(parStr, i, 1) If InStr(succStr, parCh) = 0 Then Missing = True: Exit For Next i If Not Missing Then Debug.Print node & " is senior node" Next node Set Nodes = Nothing Set Parents = Nothing Set Successors = Nothing End SubDave,
I had some minor errors in the code I listed. Primarily, the ordered pair index values should have been 0 & 1 for head and tail respectively.
Also, you’ll notice the code never does a search a separate search for nodes without parents. Since the null set is a subset of any set, the criteria for the Parent set to be a subset of the Successor set was already met.