If you like writing lots of code, TDD is for you
If there’s one thing you can’t argue about Test Driven Development, it’s that it creates more code than software written without it. Not just unit test code, either. To make code testable, developers often introduce extra layers of abstraction to make their code accessible, in isolation, from within their unit test code. This can be a good thing, but can also lead to a code explosion.
On second thought, I imagine someone actually would argue that, over time, a TDD codebase will have less code, for various reasons, possibly because it is easier to maintain, possibly because it encourages less code duplication, and so on. That’s fine, but this article is about the initial set of code that gets you to a shipping state, from scratch. We’re talking about version one point oh. The first set of working code that gets your product out the door, for the first time.
Okay, all clear?
How about an example?
Brett L. Schuchert, who publishes on ObjectMentor’s blog wrote an interesting piece of using TDD with C++ to write “Hello, world!”.
Yes, seriously: “Hello world!”
You know, the program that’s so simple, you can write it practically from memory?
With your eyes closed.
With one hand tied behind your back.
Yeah, this one:
#include <iostream>
int main() {
std::cout << "Hello, world!" << std::endl;
return 0;
}
Mr. Schuchert decided to create “Hello, world!”, from scratch, by strictly following principles from Test Driven Development. An interesting idea.
The result?
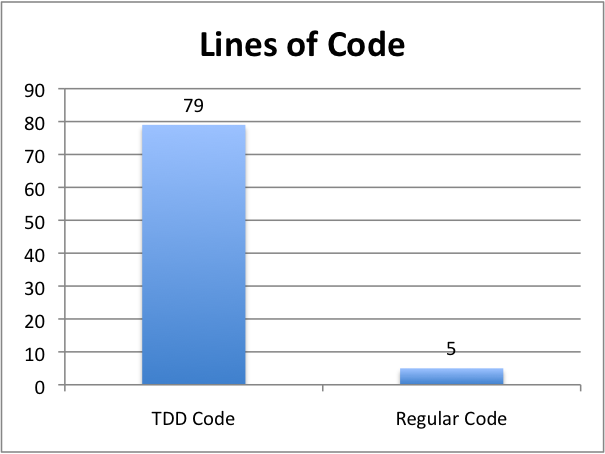
Nearly 80 lines of code, counting a Makefile that he felt compelled to create because it got too bothersome to compile with a single command.
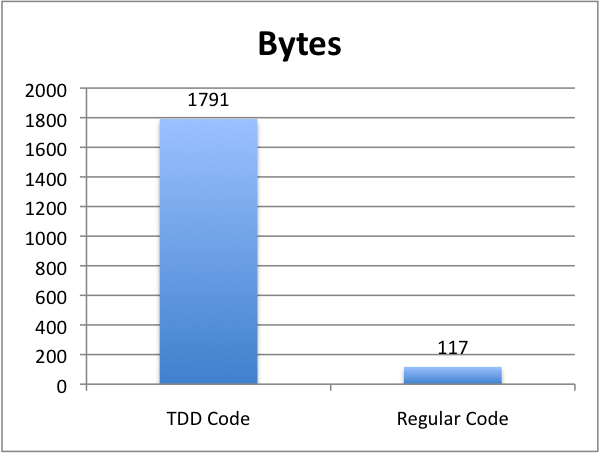
Let’s look at that visually. Here are a couple graphs comparing the number of lines of code and the number of bytes used by the two approaches, TDD vs. Regular:
After looking at this example, I’d like to consider a couple questions:
- Where would a bug most likely appear in this code?
- What are the odds of a 79-line code base containing a bug compared to a 5-line codebase?
Let’s consider these questions in order:
Where would a bug most likely appear in this code?
Of the 79 line of code in the TDD codebase, only 2 lines are actually being tested, namely:
std::cout << "Hello, world!" << std::endl;
And
return 0;
The other 77 lines of code are well represented by lines like this:
TEST(HelloWorld, CorrectOuputPutToCout) {
mainImpl(0, 0);
STRCMP_EQUAL("Hello World!\n", stream->str().c_str());
}
And this:
int main(int argc, char **argv) {
return mainImpl(argc, argv);
}
In the added TDD code, we find function calls with multiple arguments, string conversions between std::string and const char* types, unit test macros, and so on.
In this example, the added TDD code is actually more complex than the code under test. If I were a gambling man, I would bet that, given a randomly introduced bug, it would pop up in the added TDD code and not the code under test. Sadly, a bug in TDD code can render your tests useless.
What are the odds of a 79-line code base containing a bug compared to a 5-line codebase?
Unfortunately, I don’t have any empirical evidence to support an answer to this question. However, I have read and written a lot of code over the past 10 years. One thing I can say with confidence: A larger codebase is generally likely to contain more bugs than a smaller codebase. Obviously, there are exceptions to this rule. Some code is, by its nature, more complicated and bug-prone than other code. But, generally speaking, more code is likely to have more bugs than less code. In this example, we are dealing with more than a 10-fold code explosion. While I wouldn’t argue that we should expect a 10-fold bug increase, I would suggest that there will be added bugs, when compared with the smaller codebase.
But what about over time?
Yes, overtime, your unit tests, if properly written, can prevent new bugs from being introduced to existing code, for certain kinds of codebases. For, “Hello, world!”, however, this is most certainly not true. I can’t imagine a case where even the least skilled developer would introduce a bug into this code. So, if you agree with me on that statement, then the argument that TDD reduces long-term maintenance costs is completely lost on this example.
Conclusion
Mr. Schuchert argues that using TDD for this example was the “right thing to do”, I have to respectfully disagree. Mr. Schchert concludes that TDD helped by removing business logic from main(), which is generally a good thing to do. In this example, however, I disagree. I feel that the business logic (i.e., printing “Hello, world!” and returning 0) is so simple and unlikely to change in the future, that the added complexity of unit tests only makes the implementation less tractable and the code more costly to maintain. He introduces a build-dependency (the unit test framework) and added a layer of indirection for future readers to follow when learning the code. Further, the probability of introducing bugs has increased by the sheer volume of added TDD code. I conclude that while this was an interesting exercise into the TDD practice, I don’t think that TDD adds value in this example.